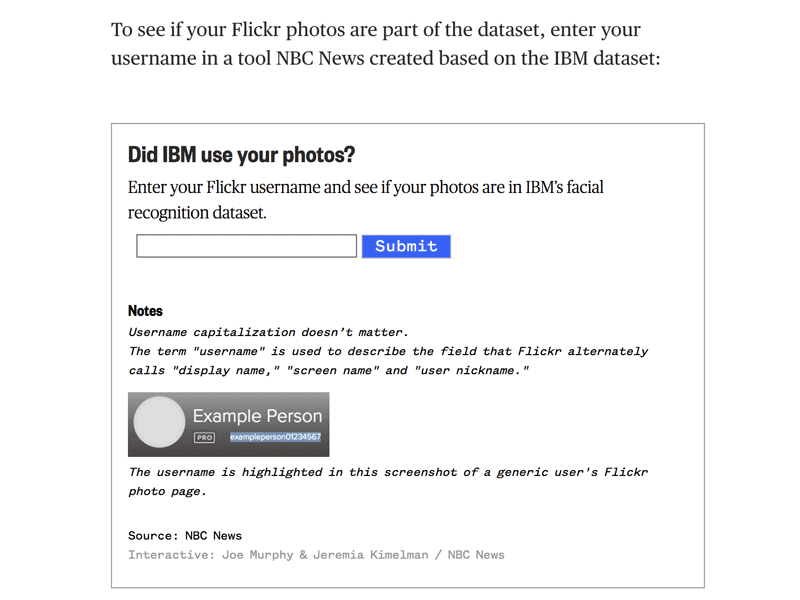
Analyzed two 50GB datasets of user and photo metadata and figured out a way to publish pieces of its contents without compromising the privacy of those in it.
What I did
- Cross-referenced two large datasets to pull a list of usernames of those affected.
- Helped plan and build the widget (front-end and back-end) used to let readers know if they were affected. We used a node script to batch upload tens of thousands of individual json files, named with a hashed and salted filename. We hash and salt the filenames in order to protect the privacy of flickr's users.
Flickr and its facial recognition database project links
Facial recognition's 'dirty little secret': Millions of online photos scraped without consent